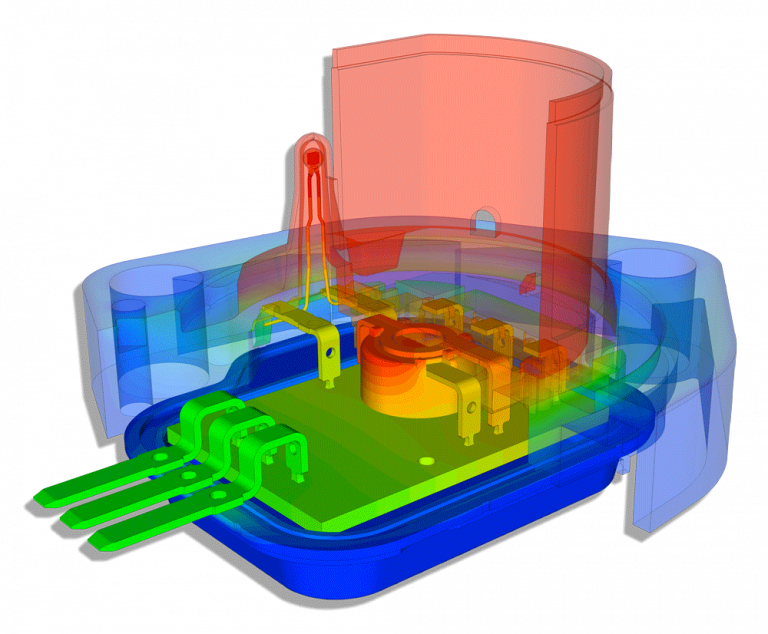
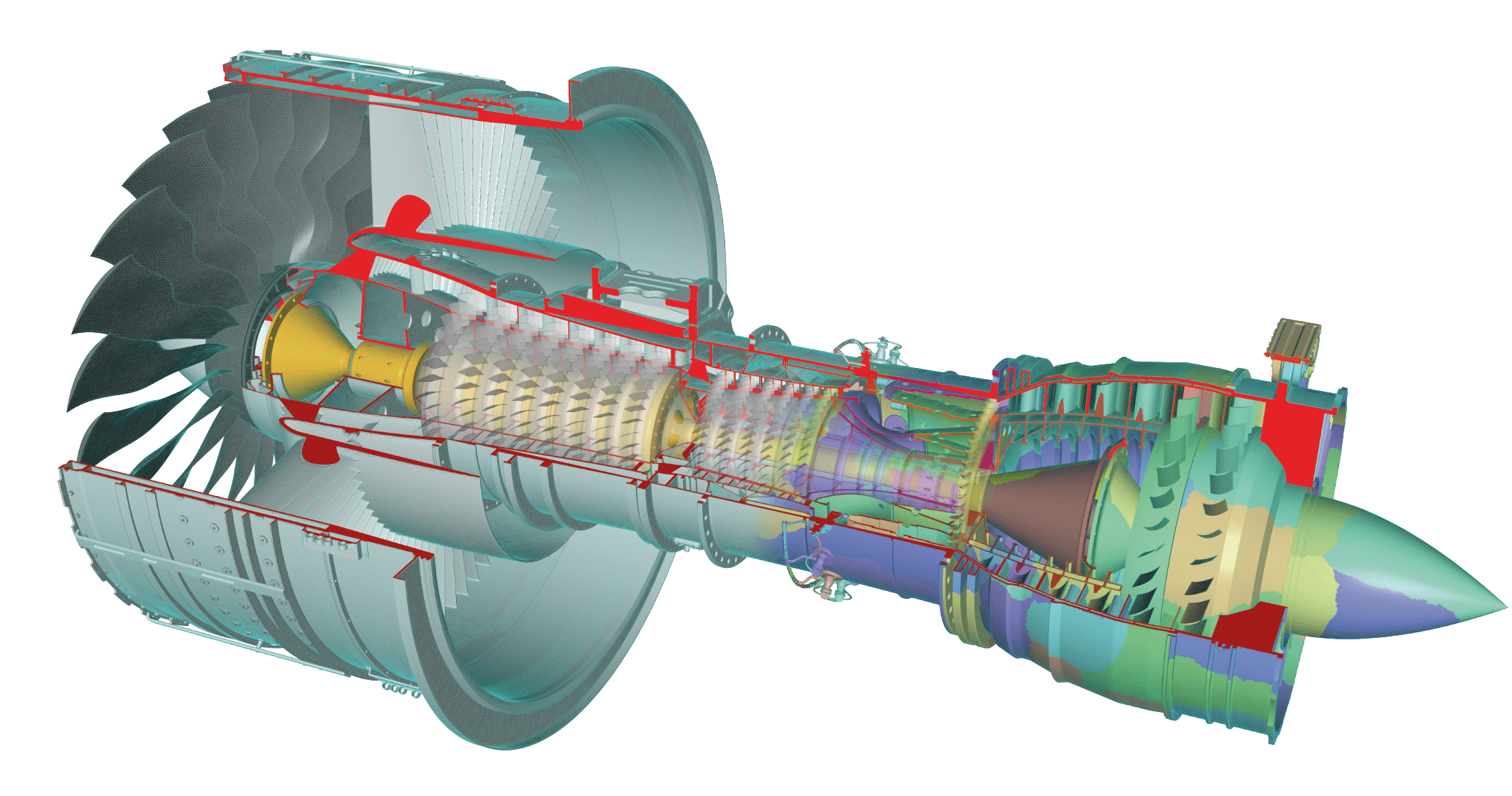
Jet Engine
sequential ASCII FEM database 150 GB
822 milion mesh nodes
mesh loaded and decomposed in 14 seconds

PreProcessing
Create unstructured meshes in your favorite robust and efficient preProcessing tool as you are used to doing, and export database files from the preProcessing tool in your preferred format.

Supercomputer
Solve the problems at the top of your database files